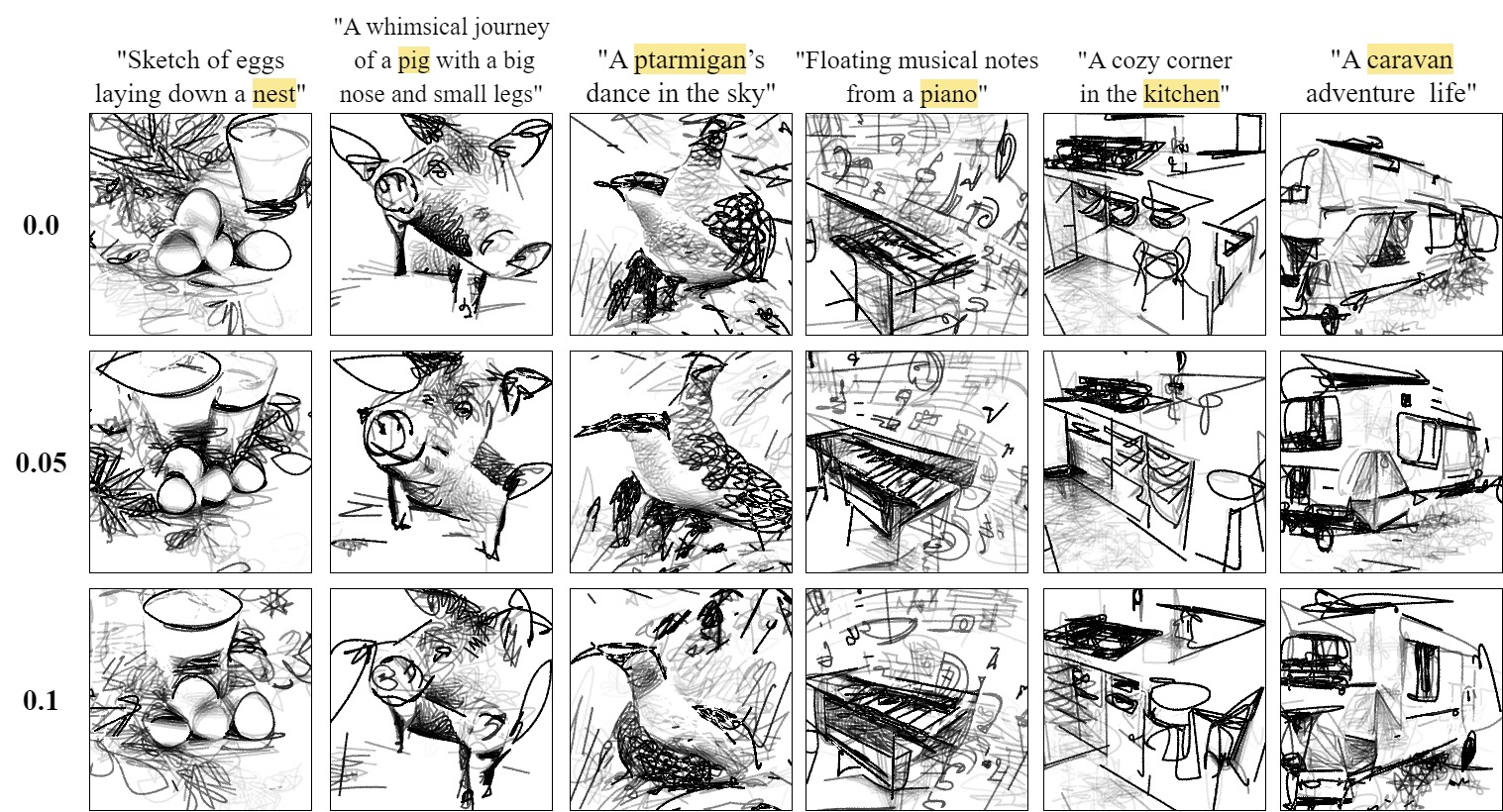
From Prose to Portraits: Mechanism of Sketch Synthesis

CLIPDraw++ comprises strategic canvas initialization, which utilizes diffusion-based cross-attention maps and a patch-wise
arrangement of primitives, along with a primitive-level dropout (PLD). The proposed model, coupled with the use of a pre-trained image
\( \mathcal{I} \) and text \( \mathcal{T} \) encoders from the CLIP model for similarity maximization, positions itself as an efficient and user-friendly tool in the
realm of AI-driven explainable sketch synthesis. The highlighted word is used to create the cross-attention maps.
The total loss, \( \mathcal{L}_\text{total} \) is the summation of two loss functions (semantic loss \( \mathcal{L}_\text{sem} \) and visual loss \( \mathcal{L}_\text{vis} \)), each weighted by their respective coefficients, \( \lambda_\text{sem} \) and \( \lambda_\text{vis} \). These two loss functions balance our sketch synthesis process: semantic loss aligns vector sketches with textual prompts, while visual loss maintains low-level spatial features and perceptual coherence. This combination effectively captures the intricate relationship between semantic fidelity and geometric accuracy.
The total loss, \( \mathcal{L}_\text{total} \) is the summation of two loss functions (semantic loss \( \mathcal{L}_\text{sem} \) and visual loss \( \mathcal{L}_\text{vis} \)), each weighted by their respective coefficients, \( \lambda_\text{sem} \) and \( \lambda_\text{vis} \). These two loss functions balance our sketch synthesis process: semantic loss aligns vector sketches with textual prompts, while visual loss maintains low-level spatial features and perceptual coherence. This combination effectively captures the intricate relationship between semantic fidelity and geometric accuracy.
$$\mathcal{L}_\text{total} = \lambda_\text{sem} \mathcal{L}_\text{sem} + \lambda_\text{vis} \mathcal{L}_\text{vis}$$
Unraveling Textual Descriptions into Artistic Creations
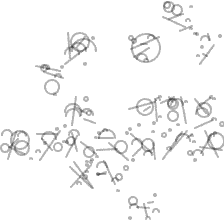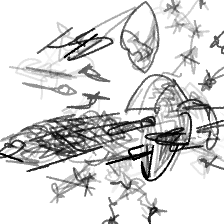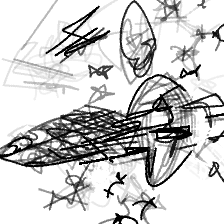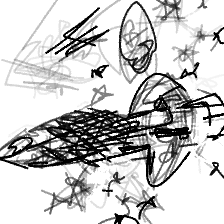
“A spaceship flying[..]” “A spaceship flying in a starry sky”

“An astronaut in [..]” “An astronaut in space”

“A camp in [..]” “A camp in wilderness”
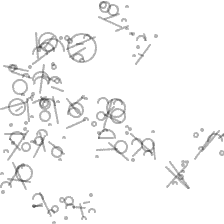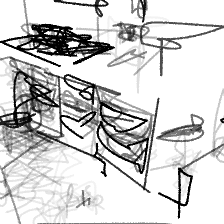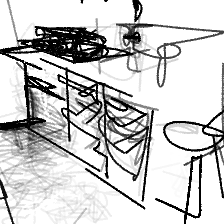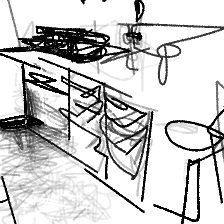
“A cozy corner [..]”“A cozy corner in the kitchen”
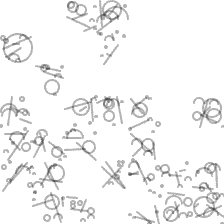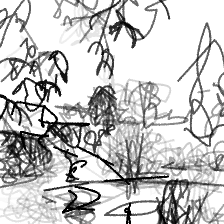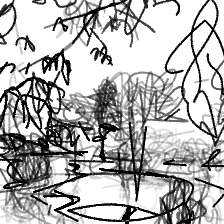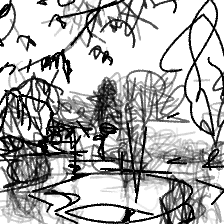
“Beauty of a secluded pond[..]”“Beauty of a secluded pond nestled in the heart of woods”
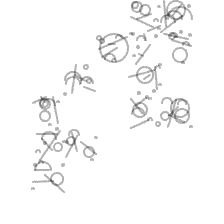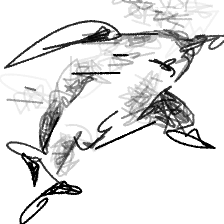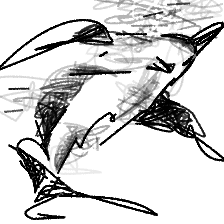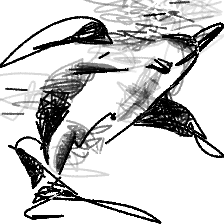
“A dolphin leaping [..]”“A dolphin leaping to the sky”
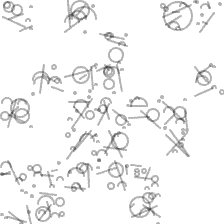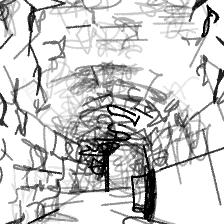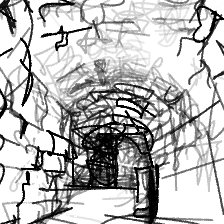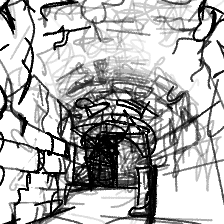
“Dark, mysterious dungeon[..]”“Dark, mysterious dungeon tunnel, dimly lit”
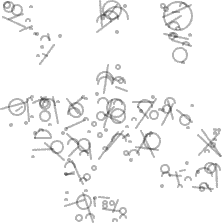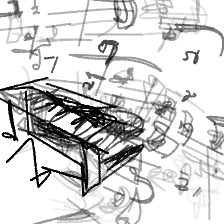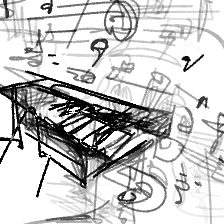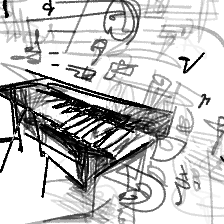
“Floating musical notes[..]”“Floating musical notes from a piano”
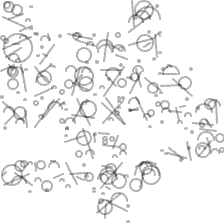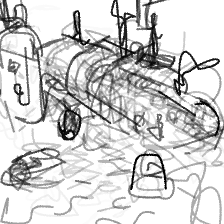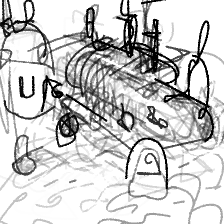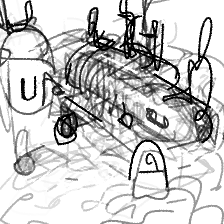
“An underwater submarine”“An underwater submarine”
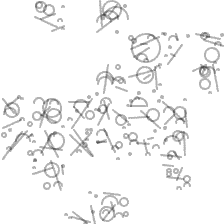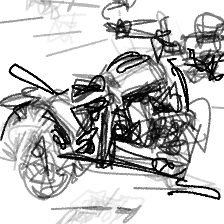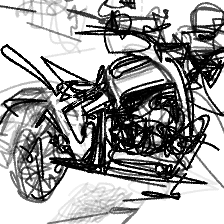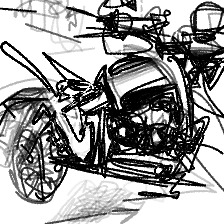
“A standing motorcycle”“A standing motorcycle”
For more results, please visit gallery!
From Doodles to Details: The Explainability of Sketch Synthesis
Our model skilfully captures the dynamics of shape or scene evolution, displaying varying levels of flexibility based on the degree of freedom, which is linked to the number of control points in a shape. In the farm example, it assigns straight lines to simpler structures like a house's roof and walls, while more complex elements like grass and crops are made with semi-circles, providing more flexibility. Even more intricate structures, like trees, are rendered using circles, the most flexible shape, illustrating the model's skill in using various primitives for different levels of complexity. This strategic use of shapes enhances the model's ability to create detailed, nuanced sketches.

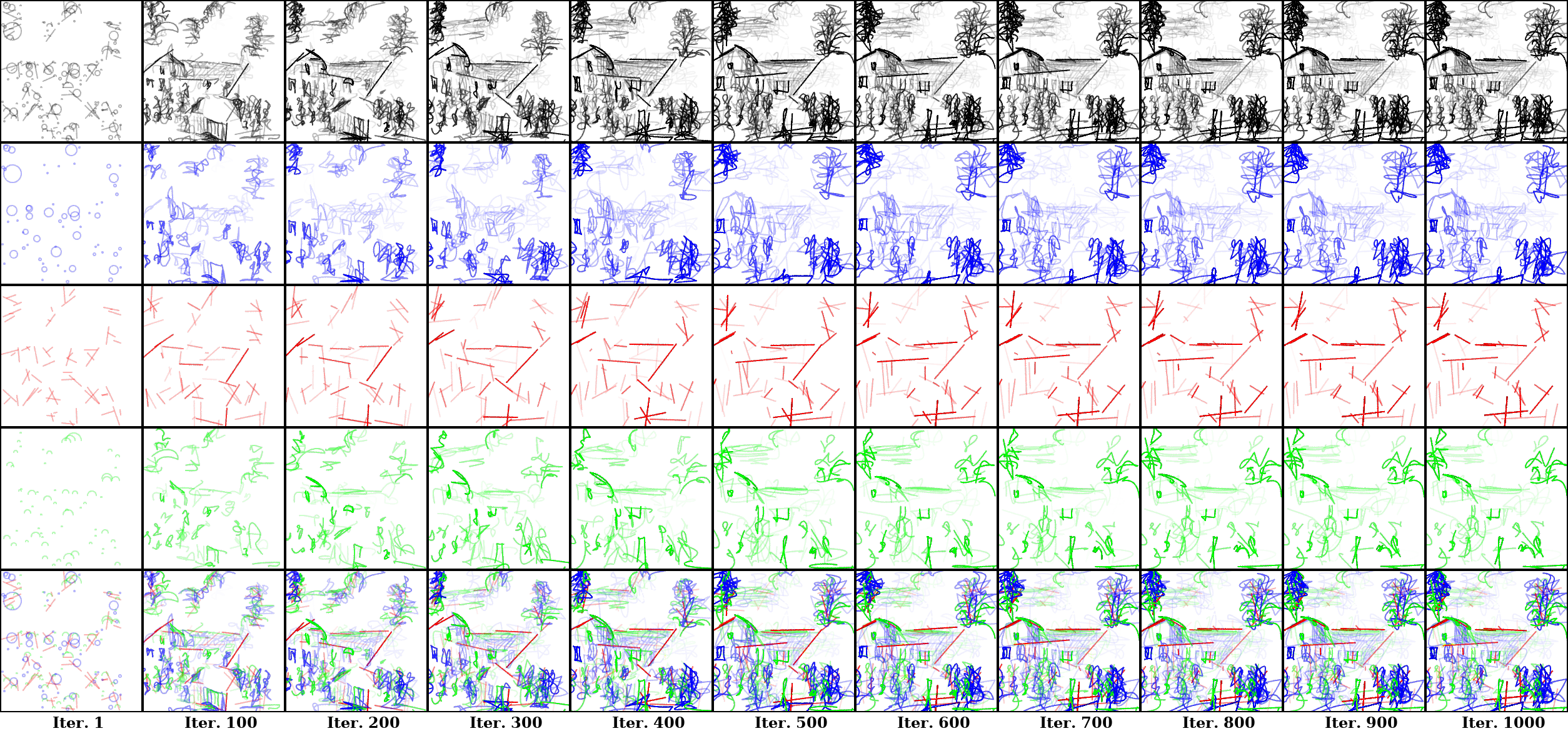
For more results, please visit Explainable Sketch Synthesis!